 Previously:
Previously:
Introduction
Single Qubit Gates
Multiple Qubit Gates
Measurement & Review
Superdense Coding
Beam Me OverIf you took the time to digest the
previous article on the Superdense Coding protocol, you'll find comparatively few surprises in this one. Remember how two entangled qubits were initially prepared in a special
Bell State; then one was sent directly to Bob, while Alice processed the second to encode two classical bits of data. Later, Bob successfully decoded those two classical bits. Didn't it seem to you as if Alice somehow reached across the divide, fiddling with the independent states of
both qubits, using some kind of
spooky action at a distance?The Quantum Teleportation protocol is a very similar trick. In fact, you could say that it's exactly the same trick, but performed in reverse. This time, using the magic of the entangled qubit pair, and precisely the same set of quantum gates as before, Alice will teleport to Bob the
full state vector of an arbitrary third qubit - using only
two classical bits of information.
There are three preliminary, new, key concepts - all related to the notion of
measurement - that we'll need in order to investigate and explain the Quantum Teleportation phenomenon today. The first of these is:
 The Measurement Basis
The Measurement BasisSpecifically, the performance of a
measurement in an arbitrary basis. Recall that in
part one we said
the labels 0 and 1 might represent unit steps in some arbitrary x- and y-directions. When later we made a measurement
in the computational basis, we were in effect holding up a filter, constraining the result to be either
0 or
1 in this sense. But we are free to change this basis!
To take a brief physical detour, suppose our qubit is a photon, and measurement involves holding up a pair of polarized sunglasses, either horizontally or vertically, to see whether or not the photon gets through the lens. We know there's a 50-50 chance it that will, simply because holding up
two such identical and overlapping lenses, one horizontally and one vertically, will prevent
any photons from getting through. But what's to prevent us holding our sunglasses at ±45° to the horizontal?
Nothing. All we're doing is changing the basis of measurement, from the original computational basis, i.e. horizontal
0 or vertical
1, to this new one, where perhaps
0' and
1' mean pointing respectively up or down at 45°. From the diagram we see these new basis vectors can be expressed readily in terms of the originals, like this:
0' = (0+1)/√2,
1' = (0-1)/√2.
But this is precisely the state transformation performed by the Hadamard gate. Now we can see that it corresponds to a particular reflection, in a line at 22½° to our basis
0 vector (the light grey line in the diagram is this axis of symmetry). Incidentally this illustrates nicely why the Hadamard gate,
like any reflection, is its own inverse; since we also have these perfectly symmetrical equations,
0 = (0'+1')/√2,
1 = (0'-1')/√2.
And just as
0' and
1' give us an alternative orthonormal basis for measuring single-qubit states previously expressed in terms of our original computational basis
0 and
1, so too are there any number of alternative bases for a given multi-qubit measurement. One important example in 2-qubit systems is:
The Bell BasisThis is today's new concept number two. Starting from any given 2-qubit computational basis
00,
01,
10 and
11, the Bell basis can be defined as
B0 = (00+11)/√2,
B1 = (10+01)/√2,
B2 = (00-11)/√2,
B3 = (10-01)/√2.
Notice that these four are exactly the states that Alice prepared last time, in the Superdense Coding protocol, by inserting either an
X or a
Z gate (or both, or neither) into the path of the top qubit of a pair - an entangled pair, which happened to have been prepared in a certain special initial state. We now recognise that state as
B0 = (
00+
11)/√2.
Exactly as before, it's easy to check by substitution that we can express the Bell state mapping the other way round, for convenience in our subsequent conversions:
00 = (B0+B2)/√2,
01 = (B1-B3)/√2,
10 = (B1+B3)/√2,
11 = (B0-B2)/√2.
Partial MeasurementsOur third and final new concept of the day is that of a
partial measurement. What happens to a composite, multi-qubit state when we perform measurements upon some, but not all, of its constituent qubits? Answer: measured qubits collapse into appropriate basis states in accordance with the probabilities in effect, while unmeasured ones continue in renormalized superpositions.
Take for example the 2-qubit state (a, b, c, d) = a
00 + b
01 + c
10 + d
11, and suppose that we perform a measurement, in the computational basis, on its first qubit. Then the probability of getting a result of
0 is simply the
sum of the probabilities of getting either
00 or
01 from a full, 2-qubit measurement. Similarly, the probability of a
1 is just the sum for
10 and
11:
prob(0?) = prob(00) + prob(01) = |a|² + |b|²,
prob(1?) = prob(10) + prob(11) = |c|² + |d|².
Okay, that tells us everything we can ever know about the first qubit. What can we say about the
posterior state of the second qubit, i.e., its state
after this partial measurement? We can answer this by rewriting the original state, collecting terms involving a result of
0 or
1 for the first qubit measurement:
(a, b, c, d) = a00 + b01 + c10 + d11 = 0 (a0 + b1) + 1 (c0 + d1).
This lets us read off the result. If the measurement yielded
0 for the first qubit, then the second qubit is now in the state indicated by a
0 + b
1, which of course we must renormalize as usual:
(a0 + b1) / √(|a|² + |b|²).
Similarly, a measurement of
1 for the first qubit implies that the second is now in this state:
(c0 + d1) / √(|c|² + |d|²).
Quantum TeleportationNow we finally have enough background to understand the
Quantum Teleportation protocol, which is illustrated in the diagram below. Alice starts with an arbitrary qubit state which I've called
ψ, pronounced
sigh, out of deference to 86 years of quantum mechanics... sorry about that!
So Alice starts with
ψ = (a, b) = a
0 + b
1, where |a|² + |b|² = 1. This is the state she wants to communicate to Bob; and she also has access to
one qubit of an entangled pair, previously prepared in the state
B0 = (00+11)/√2.
She now performs the "decoding" second half of the Superdense Coding protocol on her two qubits. So that's a
cNOT, followed by a Hadamard on the first qubit, then a 2-qubit measurement. Remember, this was the operation performed by Bob last time, and it yields a couple of classical bit results. We've shown these as thick double wires, intended to give the impression of big, strong, macroscopic classical logic levels, insusceptible to decoherence. This decoding operation is actually termed a
measurement in the Bell basis. Furthermore, in this setup it's a
partial measurement. Recall that we are dealing with a system of
three entangled qubits, but measuring only two of them. The third, the bottom one in the diagram, is simply transmitted directly to Bob.

Now Bob examines those two classical bits of data he's received from Alice, and uses them to decide which, if any, of his decoding
X and
Z gates to apply. His logic is exactly the reverse of the "encoding" step used in the first half of the Superdense Coding protocol. And that's all there is to the Quantum Teleportation protocol; the output that Bob ultimately obtains is identical to Alice's initial, arbitrary state
ψ.
I Don't Believe YouAnd who can blame you! Okay, but be warned: I'll be renormalizing throughout today, so as to avoid any sleight-of-hand accusations. So let's start with the initial state of the 3-qubit system,
(a0 + b1)(00 + 11) / √2 = [a (000 + 011) + b (100 + 111)] / √2.
Alice begins by passing the first two qubits through a
cNOT gate. This flips the state of the second qubit in the last two terms, i.e., those where the first "control" qubit is
1, resulting in the state
[a (000 + 011) + b (110 + 101)] / √2.
Next she passes the first qubit through a Hadamard. The effect of this is to replace every initial
0 with (
0+
1)/√2, and every initial
1 with (
0-
1)/√2. Collecting terms and combining the √2 divisors, we now have the state
[a (000 + 011 + 100 + 111) + b (001 + 010 - 101 - 110)] / 2.
This is the point at which Alice performs the partial measurement upon the first two qubits. The probability of her getting a result of
00 is
prob(00?) = prob(000) + prob(001) = (|a|² + |b|²) / 4 = ¼,
since |a|² + |b|² = 1. And in fact if you work out the remaining probabilities for results
01,
10 and
11, they all turn out to be ¼. Think about that - the measurement outcome is absolutely random, and completely independent of the particular state of the input qubit
ψ! This happens because - thanks to the
cNOT and
H gates - we are performing the measurement in the
Bell basis, and not in the original
computational basis where we started.
Fascinating as this detail may be, nevertheless it's not quite what we're after here. We want to know the
posterior state of the
third qubit. This does depend critically upon the particular 2-bit classical result just obtained, so just as in the Superdense Coding protocol, we now have four distinct cases to consider.
________
Case 00: keeping only the
000 and
001 terms from our state expression and renormalizing, we obtain the state received by Bob:
00 (a0 + b1) = 00 ψ.
That's the magic of quantum teleportation! Without doing anything further, Bob knows from the classical measurement
00 that
his third qubit is already in Alice's initial state, ψ.________
Case 01: keeping only the
010 and
011 terms from our state expression, and renormailzing, we obtain the state received by Bob:
01 (a1 + b0).
Notice however that the
1 bit in the classical measurement result activates the
X gate in Bob's decoding circuit, causing a logical inversion of the third qubit, and a final state of
01 (a0 + b1) = 01 ψ.
Again, Bob has successfully received Alice's full state ψ in that third qubit.________
Case 10: keeping only the
100 and
101 terms from our state expression, and renormailzing, we obtain the state received by Bob:
10 (a0 - b1).
Notice however that the
1 bit in the classical measurement result activates the
Z gate in Bob's decoding circuit, causing a sign change in the second basis component of the third qubit, and a final state of
10 (a0 + b1) = 10 ψ.
Again, Bob has successfully received Alice's full state ψ in that third qubit.________
Case 11: keeping only the
110 and
111 terms from our state expression, and renormailzing, we obtain the state received by Bob:
11 (a1 - b0).
This time both bits in the classical measurement result are
1, so this state becomes subjected to both the full logical inversion and the phase (sign) change, and the final 3-qubit state is
11 (a0 + b1) = 11 ψ.
So in all four cases - in other words, regardless of the outcome of the partial measurement operation -
Bob has successfully received Alice's full state ψ in the third qubit.________
Interactive DemoOnce again
Brad Rubin steps up with the Wolfram Demonstrations Project simulation of the
Quantum Teleportation protocol, a model of clarity:

This ingenious demo lets you vary both the arbitrary input state
ψ, by dragging the indicator point in the upper graph, and the 2-qubit partial measurement result, using the radio buttons below it. Intermediate states of the 3-qubit system are displayed as continuously updated column vectors.
Picture of Star Trek transporter chamber from Wikipedia.
 New Security Group
New Security Group
















 A crucial point here is that events are always saved and applied at the
A crucial point here is that events are always saved and applied at the 


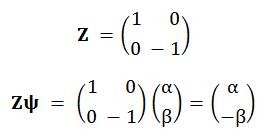








{kind=link}